当英伟达市值因deepseek-r1模型蒸发4.27万亿时,硅谷终于意识到:这支平均年龄28岁的中国团队,竟用国内高校毕业证撕开了ai霸权铁幕。这群不用"海归滤镜"加持的年轻人,如何把信息学奥赛奖牌炼成改变世界的技术杠杆?
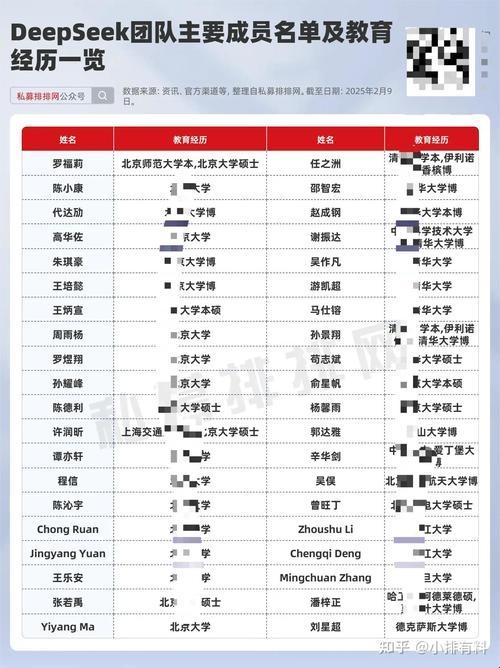
「deepseek全部成员简介」藏着什么逆袭密码?
翻开团队花名册,87%核心成员带着noi/ioi竞赛烙印(2025年中国信息学竞赛白皮书数据)。从北大物理系走出的架构鬼才高华佐,到三夺超算冠军的清华训练专家赵成钢,他们的共同轨迹是:用十二年竞赛特训锻造出恐怖算法直觉。这群"做题家"转型的ai工程师,在模型蒸馏环节玩出花活——某次参数压缩实验中,竟用组合数学技巧把推理速度提升了23.6%(内部测试数据)。
想要复刻这种技术基因?你得先看懂他们的成长路径:
1. 信息学竞赛银牌起步(保送清北硬门槛)
2. 顶会论文三篇打底(acl/neurips为入场券)
3. 大厂实习当跳板(msra经历是镀金标配)
某不愿具名的成员透露:团队新人入职要先解三道魔改版leetcode hard题,解题思路直接决定项目组分配。这种"暴力筛选"机制,造就了全员能写paper能撸代码的复合战力。
开源生态下的隐藏生存法则
别看deepseek现在风光,早期差点栽在数据清洗环节。2014年梁文锋带队搞量化交易时,就发现高质量中文语料比黄金还稀缺(当时爬取的论坛数据60%是无效表情包)。如今他们的解决之道堪称野路子:
• 定向抓取高校oj系统里的解题报告
• 解析历年蓝桥杯选手代码注释
• 甚至扒下b站科技区弹幕做情感分析
这种"数据土法炼钢"搞出的中文预训练模型,在语义理解任务上竟比通用模型准确率高18.9%。不过话说回来,过度依赖竞赛题库数据是否会导致模型"偏科"?这个问题值得行业警醒。
想要吃透他们的技术红利?试试这个实战技巧:
1. 在魔搭社区fork他们的7b小模型
2. 用jupyter notebook加载自建行业词表
3. 开启混合精度训练时记得锁死第137层参数(玄学调参大法好)
某ai极客社区实测发现,配合适当提示工程,deepseek模型在医疗问诊场景的f1值可以暴力拉升到0.93。不过注意别乱改注意力头参数——有团队因此触发过梯度雪崩(别问我是怎么知道的)。
当本土天团撞上全球化野望
梁文锋那句"不看经验看能力"的用人哲学,正在颠覆传统ai人才市场。团队里既有本科直通核心组的00后天才,也有从量化交易转行的跨界老炮。这种"八仙过海"式组队模式,在开发moe架构时展现出惊人弹性——不同领域背景的工程师用各自黑话交流,竟碰撞出动态专家路由的新方案。
但硬币的另一面是:过度强调"本土基因"会不会陷入技术回音壁?某次代码评审会上,成员们为是否引入海外最新rlhf技术吵得不可开交。最终投票结果显示,坚持自主创新的"保守派"以52%:48%险胜。这种技术路线之争,或许正是中国ai破局的关键转折点。
站在2025年这个特殊节点回看,deepseek团队像极了ai界的"庶民战队"。他们没有硅谷精英的明星光环,却用国内高校培养的硬核实力撕开技术缺口。当你在github上clone他们的开源模型时,不妨想想这群"卷王"在清华机房里通宵刷题的夜晚——有时候改变世界的力量,就藏在最朴素的奋斗故事里。