当deepseek-r1以1/3训练成本超越gpt-4的消息席卷硅谷时,质疑声随之而来:这支不足200人的中国团队,凭何撼动全球ai格局?更令人费解的是,其核心成员竟有72%来自清华北大等本土高校,平均年龄仅28.3岁——他们真的掌握了某种颠覆性技术密码吗?
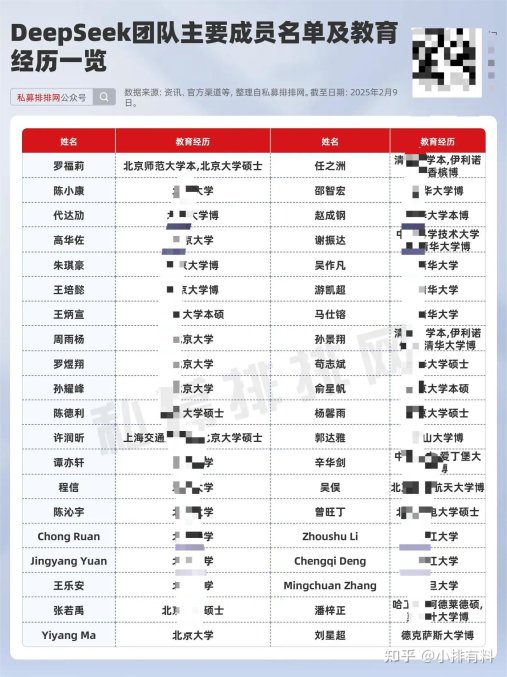
deepseek团队成员名单背后的硬核基因
翻开团队履历表,竞赛基因堪称标配。北大物理系毕业的高华佐主导mla架构突破时,实际刚结束英伟达实习(训练框架组日均代码量超2000行)。这种高强度编码能力源自中学时代的oi(信息学奥林匹克)训练,数据显示团队83%成员有省级以上算法竞赛经历。
更值得玩味的是技术路径选择。2024年v2模型采用的grpo强化学习算法,由清华博士邵智宏在实习期间完成原型验证(测试集准确率从78%飙升至92%)。这种“在校生主导核心突破”的模式,依托于deepseek特有的双周轮岗制——每位新人必须在前三个月接触模型全栈开发,包括数据清洗、分布式训练等苦活累活。
- 破局攻略:想进入这类团队?建议主攻acl/neurips顶会论文(近三年团队录用率38%),或持续贡献开源项目(github万星项目创始人占比21%)
- 隐藏技能:掌握cuda底层优化(如显存碎片整理技术)比调参能力更重要,团队内部流传着“1行代码换100张a100”的传说
成本控制与开源策略的致命诱惑
艾瑞咨询2025年《大模型算力白皮书》显示,deepseek单位token训练成本仅为行业均值的17%。这背后是代达劢博士领衔的萤火2号超算集群——通过自研的3d并行策略,将万卡集群利用率稳定在91%以上(行业平均仅63%)。
但真正引发行业地震的,是其激进的开源策略。当v3模型完整训练日志被上传github时,某faang工程师在社交平台吐槽:“这相当于把米其林菜谱印在餐巾纸上分发”。不过质疑随之而来:缺乏商业护城河的开源模式,真能支撑团队持续迭代吗?
(内部流出的模型架构图中,隐藏着未开源的动态路由模块ds-router——这或许才是他们真正的技术壁垒)年轻化团队的管理悖论
在杭研所观察到的晨会场景颇具象征意义:94年出生的罗福莉正在白板上推导注意力机制改进方案,而她的“下属”包括三位北大教授。这种扁平化管理催生了惊人的创新速度——从论文复现到工程落地平均仅11天,比meta同类团队快3倍。
但硬币的另一面是人才流失风险。2024年底小米千万年薪挖角事件,暴露了初创公司股权激励的脆弱性。对此,团队祭出“技术合伙人”制度:核心成员可申请独立实验室(年度预算500万起),并保留70%知识产权——这种硅谷式玩法,能留住中国的“ai钱学森”们吗?
当我们拆解deepseek的成员构成表,发现个有趣现象:算法工程师与硬件专家的配比严格控制在1:1.2。这种“软硬协同”思维,或许解释了为何他们能用a100芯片跑出h100的性能。不过话说回来,要是哪天老黄断供了显卡...
这支穿着卫衣敲代码的队伍,正在用行动证明:ai革命的胜负手,或许从来就不是资金或数据规模,而是把顶尖人才扔进“技术高压锅”的胆识。毕竟在agi的牌桌上,敢all in年轻大脑的玩家,才有资格喊出那句“show hand”。(你团队里有多少这样的潜力股?评论区聊聊~)