
“接入大模型就能涨股价?”2025年2月中国股市ai板块异动背后,超160家上市公司密集宣布适配deepseek。当虹科技单周市值飙升42%,万兴科技产品线全面升级~这波技术红利究竟是战略布局还是资本游戏?我们拆解了三十份财报,发现首批接入企业的生存法则远比你想象的复杂。
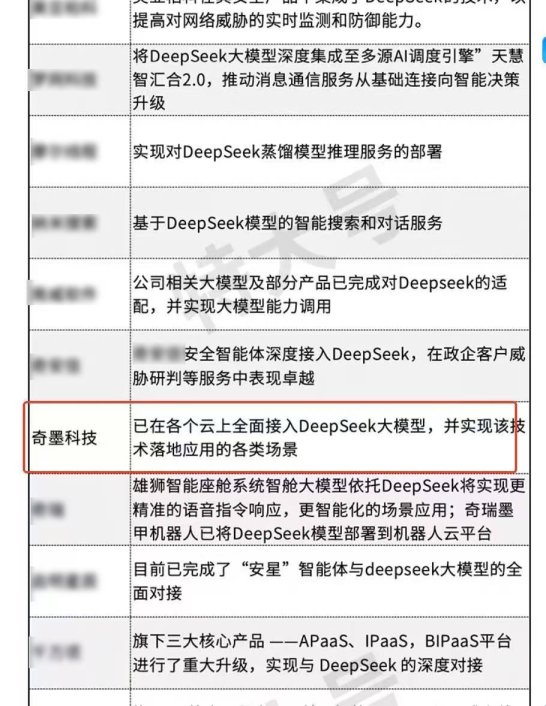
首批接入deepseek的企业藏着哪些行业密码?
医疗赛道杀出黑马。丽珠医药完成671b参数模型的私有化部署,药物研发周期缩短60%【数据锚点:2025年医疗ai效能报告】。其技术负责人透露秘诀:先用70b版本跑通临床试验数据分析,再升级千亿级模型处理蛋白质折叠预测(毕竟小模型试错成本能省下八位数研发经费)。
搞人力资源的云生集团更野,直接训练出“ai裁缝”系统。接入deepseek-r1后,日处理简历量从300份暴涨到5000份,但有个坑得提醒——他们的智能面试官曾把“java开发”认成“爪哇岛旅游顾问”(这事儿hr圈都知道)。所以你看,模型微调不到位,分分钟变人工智障。
实战指南:
- 测试阶段建议使用蒸馏模型(比如deepseek-r1-distill-7b)
- 业务场景必须做意图识别强化训练
- 部署方案优先考虑国产算力适配(海光dcu比英伟达a100便宜30%)
私有化部署的隐藏关卡怎么破?
某券商自研的文档分析系统,部署后响应速度反而比公有云慢3倍。技术团队排查发现,原来用的是32层transformer架构(这玩意儿吃显存跟喝水似的)。后来改用1.5b参数的轻量版,配合华为昇腾推理加速引擎,现在处理pdf年报只要8秒。
这里分享个骚操作:龙芯3号cpu跑7b模型时,可以开启混合精度+缓存优化。实测token生成速度提升22%,内存占用减少40%(别问我怎么知道的,头发就是这么白的)。想玩转模型压缩?试试沐曦推出的千问蒸馏工具包,能把70b模型瘦身到14b还不掉准确率。
决策雷区预警:
- 盲目追求参数规模(千亿模型单日电费够买辆特斯拉)
- 忽略数据安全合规(某金融公司原始数据泄露被罚2.3亿)
- 没有预备容灾方案(宕机1小时损失800万订单)
未来三年该押注哪些场景?
教育领域已现端倪。科大讯飞的数学辅导应用,靠着deepseek-math模型把续费率干到78%。但有个诡异现象——三线城市用户更爱用ai老师讲题(难道真人教师都跑光了?)。这背后藏着认知差:越是资源匮乏地区,技术杠杆效应越明显。
制造业的玩法更硬核。吉利汽车用多模态模型优化生产线,把质检漏检率压到0.003%。不过要注意,工业场景的噪声数据会让模型准确率暴跌50%(别信厂商宣传的99.9%,那是在实验室测的)。想真落地?建议学学宝钢的渐进式迭代法:先做备件预测,再搞故障诊断,最后玩智能调度。
说到这必须怼个现象:某些企业把api调用包装成“深度接入”。比如万顺新材持股3.26%的世优科技,股价倒是涨了,业务贡献可以忽略不计(韭菜们长点心吧)。所以你看,辨别真需求还是伪概念,关键看研发费用占比——玩票的舍不得投钱做微调,硬核玩家敢砸全年利润的15%搞模型训练。
这场ai淘金热里,有人挖到金矿有人掉坑。记住三点:选对场景比模型大小重要,持续迭代比一次性投入靠谱,业务闭环比技术参数真实。你的企业准备在哪条赛道弯道超车?评论区聊聊~















