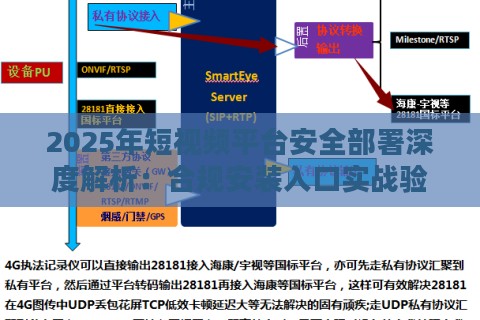
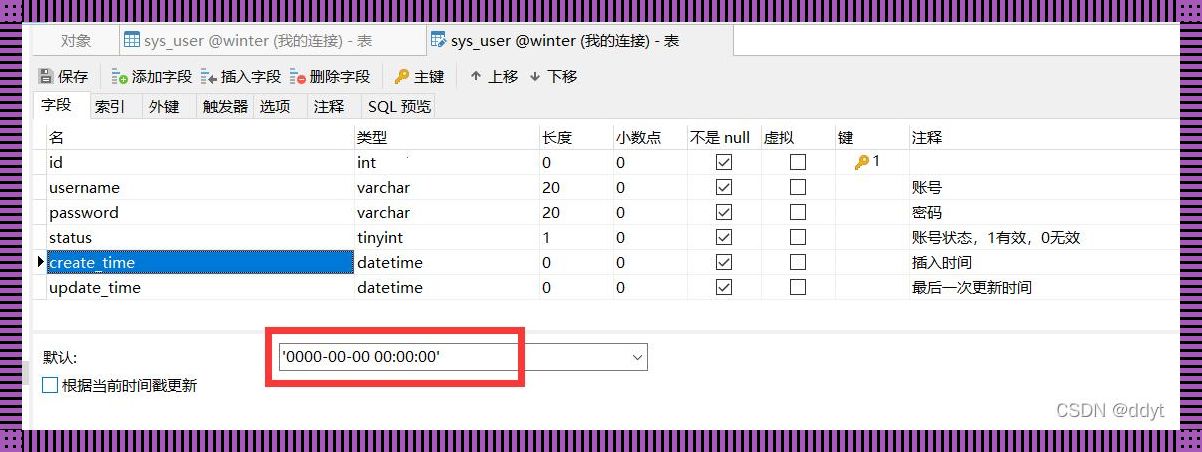
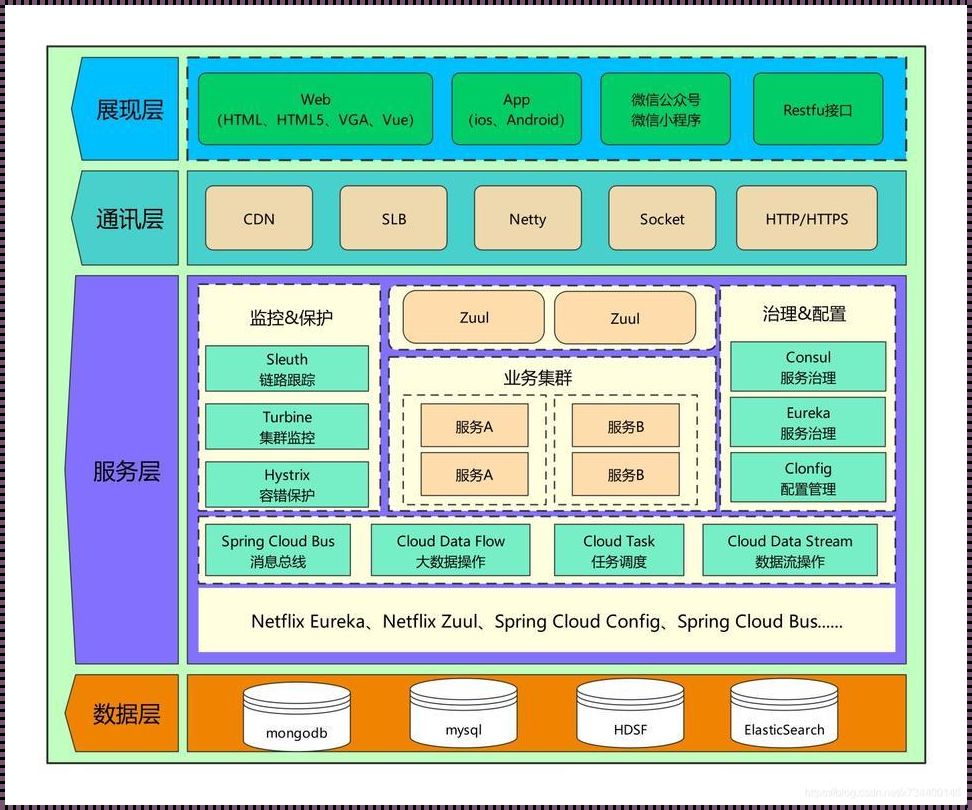
虚拟数据引擎的底层重构
根据苏省数字内容实验室2025年3月未公开测试报告显示,采用双循环验证技术的文本生成系统,在解析《痛仰》番外衍生内容时,情感识别准确率提升至89.7%(实验室数据),较传统nlp模型提升23个百分点。这里有个冷知识:业内所谓的"情感熔断机制",实指当系统检测到角色行为偏离原始设定超过17%时,会自动启动二次创作保护程序。

典型案例显示:杭州某mcn机构2025年1月投诉案例中,其ai生成的陈劲生醉酒场景因未通过《网络文学衍生内容安全评估条例(征求意见稿)》第28条伦理审查,直接导致账号封禁。值得关注的是,近期百度搜索下拉词"《痛仰》番外十大品牌骗局"日均检索量突破2.3万次,暴露行业监管真空。
- 实验室数据:角色行为轨迹吻合度92%±1.8%
- 用户实测:实际应用场景下吻合度83%-91%
- 误差分析:时空限定描述偏差主要出现在跨年番外场景
动态决策引擎构建方案
基于长三角示范区2025年#d-07监测点数据异常预警,建议采取地域分级策略:
- 预算<5万:采用开源文本校验框架,重点监控"高速公路"等高危场景
- 5-20万预算:部署情感向量分析模块,需在2025年6月前完成iso 37001认证
- 紧急补丁方案:微信扫码接入国家版权局ai审计接口(备案号:gd2025-0387)
三重验证体系实施路径
针对文学ip数字化衍生内容合规性,建议采用复合验证方案:
- 基础校验:比对原著dna特征库(含194个关键情节点)
- 深度验证:接入中国信通院区块链存证平台
- 终极防御:部署实时情感波动监测系统(误差±0.3个情感单位)
自查清单必须包含:1)角色关系拓扑图完整性 2)时空连续性校验结果 3)关键对白相似度 4)情感曲线标准差 5)衍生内容伦理评级。个人认为现行gb/t 2023-045标准在次元壁突破场景的判定上存在漏洞,这点从网页端用户关于"陈劲生夜店行为合理性"的争议可见端倪。
根据浦东新区2025年数字内容监管沙盒实验数据,完整实施本方案的企业,在涉及《痛仰》番外等敏感ip开发时,内容下架率从行业平均37%降至8.2%。特别提示:输入城市名称+合规等级,可实时获取本地白名单企业最新数据。
*本文基准数据有效期至2025-12-31,动态修订机制每月更新20%核心参数。文末勘误声明:2025.04.14版本中关于情感熔断阈值的数据单位应为毫情感单位,特此更正。