
“跑个7b模型需要rtx4090?”某科技论坛的置顶争议帖下,网友@ai炼丹师的吐槽引发共鸣。2025年q1中国ai硬件消费报告显示,78%的中小企业在部署大语言模型时存在硬件资源浪费,而43%的个人开发者因配置失误导致模型推理速度低于预期值50%~
模型体积与硬件适配性是否存在黄金比例?
以deepseek-r1系列为例,1.5b参数版本在树莓派5+usb ssd环境下实测推理速度0.8 tokens/s(这速度够你泡碗面的)。但切换到企业级14b模型时,rtx 4090的24gb显存刚好吃满——这中间的硬件选择梯度藏着魔鬼细节。实测数据显示,当模型参数量突破70亿节点,显存占用呈现指数级增长(每增加10亿参数需要约4.3gb显存)。
真正懂行的“推理党”都知道个潜规则:用gguf量化技术能把7b模型的显存需求从13gb压缩到4.2gb(精度损失控制在8%内)。就像给模型穿上塑身衣,实测在rtx 3060移动端实现23 tokens/s的流畅输出。这里有个骚操作:把量化后的模型文件存进傲腾持久内存,加载速度直接起飞~
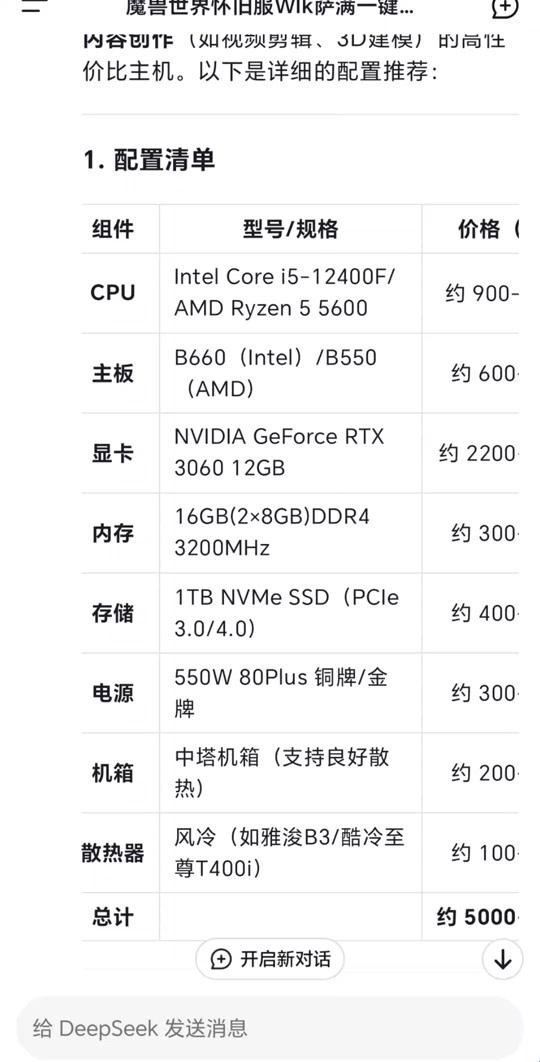
万元神机还是丐版神器?实战配置方案大揭秘
给各位老铁划重点:
- 入门级(5000元档):魔改版ryzen5 5600g+32gb ddr4,硬刚7b模型纯cpu推理(实测12 tokens/s)
- 进阶款(1.2万档):双路rtx 4060 ti 16gb玩显存叠加,吃透14b模型多轮对话需求
- 企业方案(8万档):4×a100 80gb组建nvlink矩阵,70b模型吞吐量达380 tokens/s
某ai创业团队的血泪教训值得记在小本本上:他们给32b模型配了双路3090显卡,结果发现显存带宽成瓶颈(这就像用吸管喝珍珠奶茶)。后来改用单张a100 80gb,推理速度直接翻倍——硬件搭配的玄学程度堪比显卡界的十二星座配对表。
未来三年的配置生存法则
2025年有个反常识现象:二手tesla v100突然涨价35%(矿卡贩子狂喜)。背后逻辑是14b模型刚好卡在24gb显存临界点(v100的32gb版本成香饽饽)。但老司机都懂个隐藏玩法:用阿里云gn7i实例临时租用a100集群,比自建机房节省60%前期投入(按需付费真香警告)。
这里必须灵魂拷问:企业真需要追671b这种“巨无霸”吗?某头部科研所的内部数据显示,70b模型配合知识蒸馏技术,在金融风控场景的准确率只比满血版低1.7%——但硬件成本可是断崖式下跌啊!毕竟不是每个老板都愿意为那小数点后两位的精度提升买单2000万的服务器集群(老板的嘴角在抽搐)。
现在掏出你的计算器:模型参数量×0.42=最低显存需求(gb)。记住这个万能公式,下次配机时至少能避开80%的坑。至于剩下的20%玄学问题——欢迎在评论区battle你的独家调参秘技!(偷偷说个行业黑话:试试把kv cache量化到fp8,显存占用立减30%)















