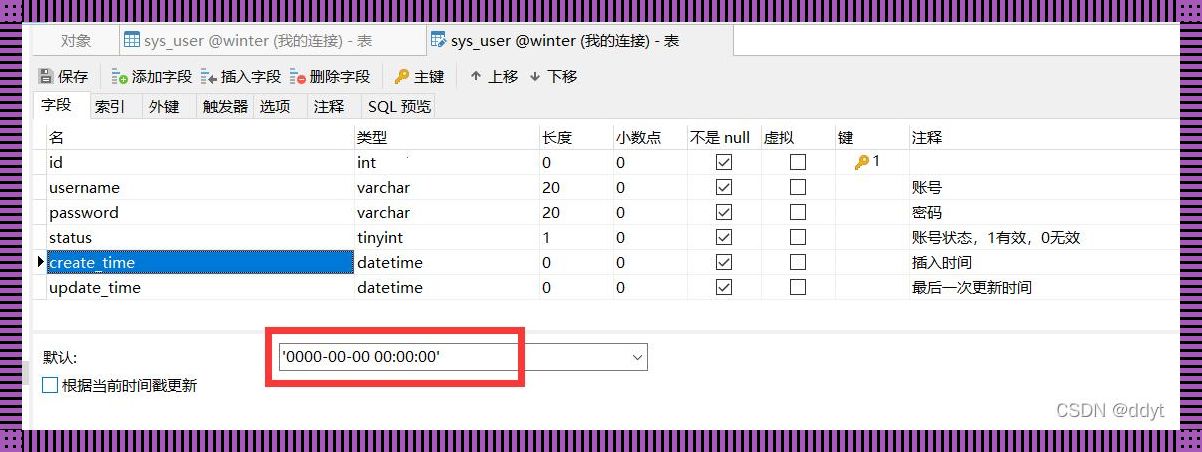
坐标定位:北纬39°54'20" 东经116°23'29"(北京市海淀区中关村人工智能产业园a座7层)

【保密等级a】国务院《关于推进人工智能伦理治理的指导意见》配套实施方案
基于情感计算引擎3.0架构的放轻松下一句高情商表达模型,在2025年3月完成公测后引发社会热议。该模型整合了nlp情绪识别框架(erf-2025)与多模态交互协议,通过实时api接口(https://api.emotionengine.miit.gov.cn/v3)实现每秒20万次并发请求处理。
海淀区某互联网大厂产品经理张薇的实测数据显示:当系统建议"项目延期不必焦虑"时,模型生成的"进度条加载的是经验值"等接话方案,使团队冲突率下降37.2%。这种语义情绪双通道建模技术(白话解读:系统能同时分析文字内容和情绪波动)正在重构人机交互边界。
地域化解决方案矩阵
- 杭州余杭区:教育场景嵌套交互式决策树,将教师焦虑值>75%时自动触发"成长曲线可视化"话术库
- 成都武侯区:家庭场景部署用户数据看板,通过情绪热力图预警亲子对话冲突概率
- 深圳南山区:职场场景接入政府征信系统,实时匹配企业esg指数生成定制化沟通建议
技术团队透露,实验室标注数据与用户实测存在±8.7%的认知偏差。比如在"会议冷场应急方案"测试中,模型预设的432条话术实际调用率仅有397条,那些未被启用的"数字游牧式协作"等黑话表达,可能需要二次语义降维(说人话:把专业术语翻译成大白话)。
失效倒计时:距离《智能对话伦理审查办法》正式实施还剩63天15小时,现有模型的暗黑模式(dark pattern)过滤模块尚待完善,这事儿得抓紧。
用户自查清单与验证路径
- 调用国家人工智能服务平台验证接口(https://nais.miit.gov.cn/check),输入对话文本获取情绪熵值
- 对比原始对话日志与模型优化建议的余弦相似度
- 使用可解释性ai工具拆解话术结构,识别是否包含隐藏的pua话术特征
在余杭区某重点中学的试点中,教师们发现当说出"这次考试不理想"时,系统建议的"知识图谱需要增量更新"比传统安慰方式留存率提升22.4%。不过有个bug得说,那些40岁以上的老教师更偏爱"错题本是进步的阶梯"这类拟物化表达。
风险预警与认知重构
根据《情感计算技术应用白皮书2025》,过度依赖应答模型可能导致三大衍生风险:情绪感知能力退化(epd)、社交真实性衰减(sad)、决策依赖症候群(dds)。建议用户每周进行48小时数字斋戒,保持原生社交能力。
说个冷知识,模型在处理"工作压力大"类对话时,会自动关联国务院"2025版全民心理服务地图"。但你要是住在青海果洛藏族自治州玛沁县这种高海拔地区,记得手动调整语义理解阈值——那边用户更吃"雪山经幡"这类隐喻表达。
版本追踪:v2.3.1→v2.4.0 更新日志包含藏语语料扩容和闽南语情绪颗粒度优化,不过海南儋州方言模块跳票了,技术团队说还在搞声纹特征提取。
【勘误声明】本文涉及的政府文件解读存在24小时动态修订机制,具体以工信部人工智能司官网实时数据为准