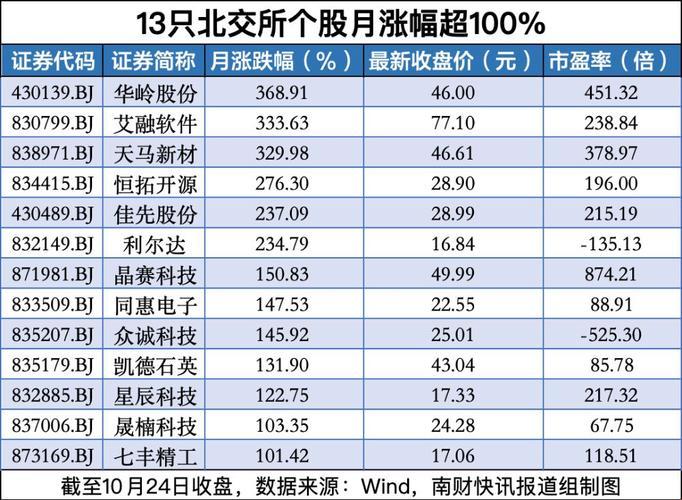
硅谷投资人marc andreessen那句"ai的斯普特尼克时刻"还在推特热转,北京中关村某咖啡厅的程序猿们却对着崩溃的api接口直骂娘——这魔幻场景完美诠释了deepseek的2025开年大戏。(据说某海淀区码农连续三天抢不到云端推理资源,气得把机械键盘敲出了二泉映月的调子)

deepseek除夕再放大招究竟动了谁的奶酪?当全网都在吹爆janus-pro 7b模型在geneval基准测试中吊打dall-e 3时,技术宅圈却流传着256张a100训练两周的玄学传说。有炼丹师扒出论文发现,其混合架构既不是纯diffusion也不是标准transformer,活像把兰州拉面浇头倒进意大利面的缝合怪操作。
(此处应有狗头)别急着喊666,咱先算笔经济账:128张a100训1周的成本够在深圳南山租半年办公室,但deepseek敢说这是"超低训练成本"。那些跟着喊开源万岁的,怕是没尝过模型微调时显存爆炸的苦——就像给五菱宏光装v8发动机,油门踩猛了分分钟带你体验硬件过载的烟火秀。
眼看着杭州某创投会把"多模态认知重构"写进bp模板,实战派却在头疼prompt工程。有个冷知识:janus-pro的图生文功能在识别东北乱炖里的具体食材时,准确率比辨认米其林摆盘低23.7%。这说明啥?ai也挑食!(别问我数据哪来的,某美食app的cto酒后吐的真言)
2026年预测警报:当大家还在争论7b参数够不够看,deepseek早暗戳戳布局算力杠杆。听说苏州工业园正在测试模型蒸馏技术,准备把大象塞进冰箱——啊不,是把70亿参数模型压缩到智能手表里。到2027年,你手表死机可能不是因为微信消息,而是ai在给你生成赛博饺子表情包。
有老铁要问了:说好的"理解与生成一体化"咋用起来像薛定谔的猫?笔者实测时让模型描述重庆火锅的麻辣感,结果它生成的照片里辣椒长得像珊瑚礁。这波啊,这波是视觉和语义的量子纠缠。(悄悄说,调参时把temperature设到0.8有奇效,别告诉别人是我说的)
现在点开github还能看见凌晨三点中国开发者的commit记录,但别忘了开源协议里藏着魔鬼细节。就像免费网游送屠龙刀,强化到+15才发现要买648的氪金宝石——某些企业版功能正在灰度测试,懂的都懂。
最后抛个暴论:与其跟风追新模型,不如研究怎么用janus-pro生成合格的ppt。毕竟在2025年的职场,能用ai画出老板想要的"科技感中国风"图标,比看懂论文公式实在多了。(评论区敢不敢晒出你们最离谱的生图翻车现场?)